

[Video transcript] Alright guys. It’s Dax Castro and once again I am here to help you tackle the tags tree and lead you down the road of remediation. Our topic today… Understanding the PDF Tags Tree.
We are going to break this down into three basic sections. Container or structural tags, Heading tags, and Nested tags for things like lists and tables. By the end of this video you should have a basic grasp of what tags are and how they are used.
Alright, lets get started.
What are tags?
Tags are the containers that store all the meta data for the objects inside our PDF. They help us organize the information so that screen readers and other assistive technology can interpret the document content and understand the relationship between objects on the page.
Web content has more than 200 possible tags. Thankfully a PDF document, at this point in time, uses only about 30 tags. Hopefully in the near future there will be support for more tags that will allow us to further control content and provide a better, more robust user experience. On to our first group of tags.
Container tags

The sole purpose of container tags is to help organize our content into basic groups. Screen readers ignore container tags, but without them as remediators, our jobs would be much harder.
Every document should start with a <Document> tag. This is the only real hard and fast rule for container tags. All the other tags are fairly interchangeable and they can be used based on the preference of the remediator and the organizational style of the document.
If we are going largest to smallest, the next in line would be the Part tag, followed by the Article Tag and finally Section tag. The use of these last three will largely depend on the source document from which the PDF was generated. Div tags can be used for things like setting language attributions for blocks of text, but we will save that for a future video.
Indesign might give you more Article tags because the designer used them to set the read order. Powerpoint will give you Section Tags. One for each slide. The question you need to ask yourself is “How am I going to organize my document?” And the only thing you need to consider is “Am I being consistent in my tag structure?” Consistency equals sanity. Especially when remediating in a team environment. The next set of tags are Heading tags.
Heading Tags
These are the most straightforward but sometimes cause the most headache when dealing with a document that you didn’t design or that weren’t clearly thought out.
The basics rule is that Headings need to be in a logical order and cannot skip over tags. They can however step back. So you can have a structure like H1, H2, H3, H2, H2, H3. But you cannot leapfrog over a tag structure. Meaning you cannot have H1, H2, H4. This can be extremely frustrating when someone has manually tags all the “notes” in a document as H4s no matter what the heading structure is for that section. Or when they have an inconsistent heading structure within the document. Also, remember that a PowerPoint document will never export with an H1 tag. So you must always go into the title slide and change the first H2 to an H1 to pass the accessibility checker. All documents must have at least one H1 tag.
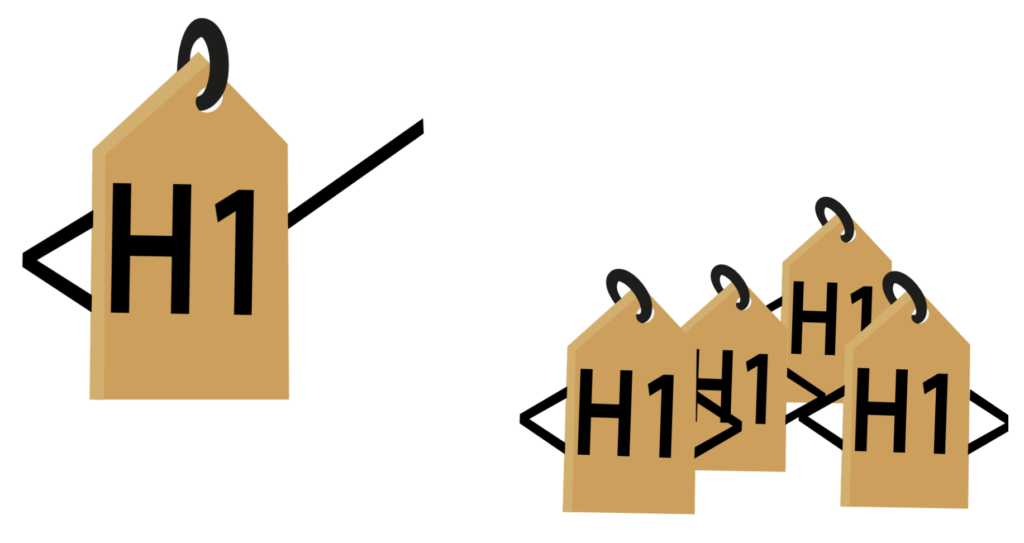
Speaking of H1 tags. Let me set the record straight. The myth that your PDF can only contain a single H1 tag is false. That rule is specifically for HTML markup. As long as your heading structure is consistent, you can have one H1 or an H1 for every page if the structure calls for it.
If I can give you one piece of advice, it is that planning your heading structure ahead of time and staying consistent, can save you hours of hunting down and fixing appropriate nesting errors.
The last set of tags are Nested tags. These are tag structures that need to follow a set of specific nesting rules. Meaning, they have a parent tag and specific peer and child tags in order to pass the accessibility checker. These tags are things like lists, tables, and table of contents. Lets take a quick look at each one.
Lists

Lists start with the <L> tag. L for list. Inside the List tag are List Items signified by the <LI> tag. LI for List Item. Inside each List Item at minimum is the <LBody> tag. This tag contains the actual text and sometimes the bullet icon as well. This is the simplest form of a list structure. However to be perfectly semantic and ISO 32000 compliant according to section 14.8.4.3.3, list items states that your <LI>tag should contain an <Lbl> or Label tag that houses just the bullet symbol as well as the <LBody> tag that contains just the text. This is especially important when you need to target your bullet symbol with alt-text because screen readers will announce this symbol > as right-pointing pointer instead of bullet” and no one wants to hear right pointing pointer 100x throughout a document.
For more info on bullets and how they are read, check out my blog post entitled “Right pointing pointer.” Our next nested tag structure is the Table.
Tables
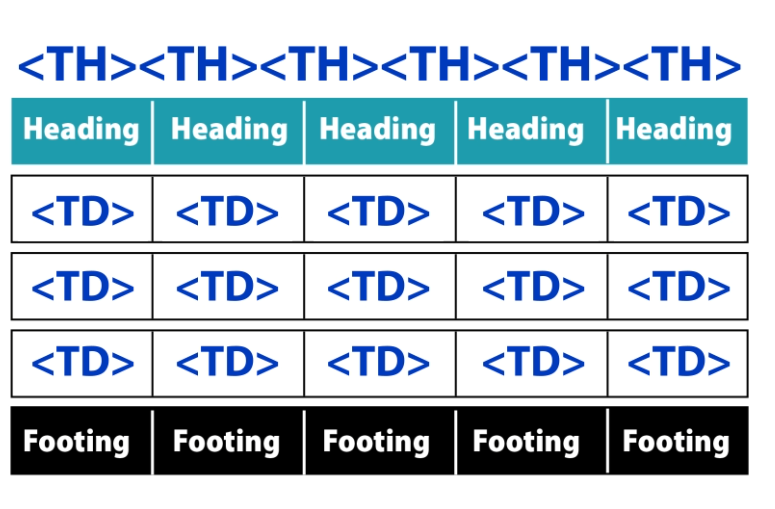
To make this easy lets first identify the structure of a table. We have the table itself which is made up of table rows. These rows contain headings, footings or table data. So let’s apply that to the the tags tree. The parent structure of table is in fact the <Table> tag. Inside our <Table> tag we have our Headings, Footings and our Body area. These are represented by the <Thead> <TFoot> and the <Tbody> tags. Inside these structural tags we have table rows which are defined by the <TR> tags. TR for Table row. Inside our <TR> tags we can have either <TH> for Table Heading tags or <TD> for Table Data tags. Remember to be PDF/UA compliant no element should be inside our <TR> tags except <TD> or <TH>. Sometimes depending on the program you might find a <P> tag inside the <TR> that contains the word “path” or pathpathpathpath” These are your table borders and for now, the only way to make tables like this PDF/UA compliant is to select and artifact each one of these elements. Yes, I know. Frustrating, but hopefully this will change in the near future.
Is your brain about to explode yet? I know this is a lot of information but the good thing is that you can watch this video over and over again until it all starts to make sense.
Well, I am sure you’ve definitely had enough brain food by now. It is probably a good idea to go back and watch the sections of this video again. You might even try writing down the tag structures as you go. Use whatever method will help you best.
Summary
I hope this video took some of the mystery out of the tags tree for you. I’m Dax Castro and as always I am here to help you tackle the tags tree and lead you down the road of remediation.
For more information join our Facebook group PDF Accessibility or subscribe to my blog at section5oh8.com. Until next time. Happy Tagging.